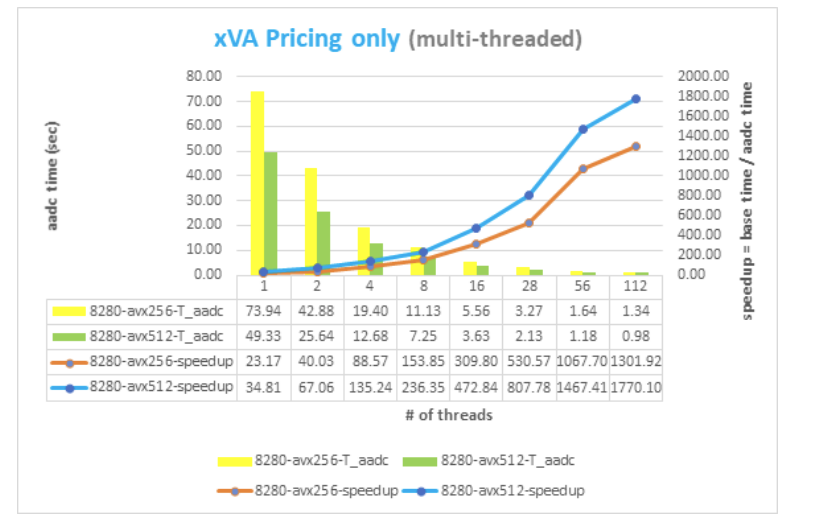
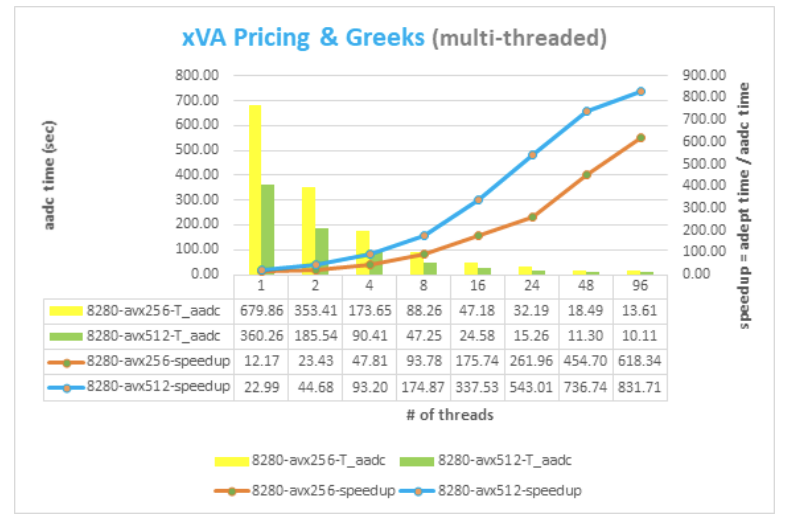
In the provided source code, the user's analytics is assumed to be implemented by the xVAProblem class in single-thread mode. It uses a template type for all real values and can be instantiated using native double type as well as active type idouble.
Computations which use native double instance set the performance baseline of the benchmark, with the baseline execution time measurements taken using a single CPU core and relying on the compiler (Intel C++) to do all vectorization work.
Using operator overloading technique with the idouble active type on the xVAProblem class allows AADC to extract the valuation graph and form binary instructions that replicate user analytics at runtime.