

Follow-up to Post 1: “FRTB Isn’t a Modelling Problem. It’s a Compute Problem.”
The most common response to my last post was some version of: “We know AAD is better. We can’t get there from here.”
I get it. Most pricing libraries are 15 to 20 years old. Validated, audited, wired into every downstream system. Nobody is rewriting them. I wouldn’t ask anyone to.
But “we can’t get there” assumes AAD requires a rewrite. It doesn’t.
The graveyard of AAD projects
The industry has been trying to adopt AAD for over a decade. Most attempts stalled.
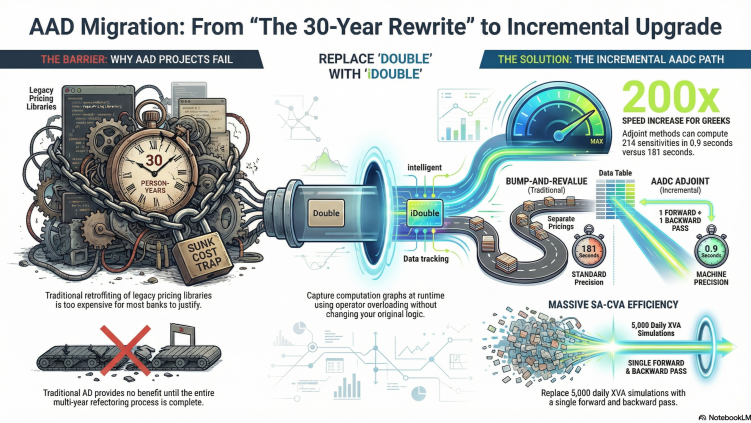
Francois Bergeaud, head of XVA quant analytics at RBS, publicly estimated the cost: 10 quants for three years to retrofit their pricing library. Thirty person-years. Most banks heard numbers like that and stopped looking.
UBS built a workaround specifically to avoid what Risk.net called a “top-to-toe overhaul of pricing code.” Barclays went a different direction entirely, publishing a paper on smart path allocation as an alternative to AAD. The speedups were comparable. The integration cost of actual AAD was too high to justify.
Even Google had a go. Their tf-quant-finance library was supposed to bring differentiable pricing to TensorFlow. It never left version 0.0.1-dev. It’s now archived. No bank shipped anything with it.
Everyone who tried to make an existing library fully differentiable from scratch either gave up or spent years getting partway there.
One team got it right
Danske Bank, 2012 to 2014. Antoine Savine, Brian Huge, and Hans-Jorgen Flyger built production AAD for their derivatives desk, and it worked. They won Risk.net’s In-House System of the Year in 2015.
Antoine later wrote Modern Computational Finance, which documents every hard lesson from that implementation. What Danske proved is that the economics are real. The question was always how to shorten the path for everyone else.
Why those projects failed
They all tried to refactor the entire library before turning AAD on. Templating every function, smoothing every discontinuity, rewriting every branch. The work keeps expanding. Two years in, you still haven’t computed a single Greek via adjoint. The refactoring never ends, so the payoff never arrives.
With traditional AD libraries, this is unavoidable. The forward pass with the AD type is slower than plain double because of tape recording overhead. You only benefit once you switch to adjoint Greeks. So the entire refactoring investment is sunk cost until you flip the switch.
What the migration actually looks like
The approach we use works differently. The recorded kernel replays with SIMD vectorization, so even a forward-only replay is faster than your original double code. You start getting value before you touch Greeks.
You take your existing pricing function. You change double to idouble. You record the computation. You replay it.
Same code, same validation. Operator overloading captures the computation graph at runtime, without source transformation or compiler plugins. Your existing tests still pass because the code hasn’t changed. The type has.
Integration scripts handle the mechanical parts. Cohort mirror debugging checks that the idouble path matches the double path to machine precision, and tells you where if it doesn’t.
The transition has a natural intermediate step. First you validate: record with idouble, replay forward-only, compare against your existing double path. Then use the recorded kernel for your existing bump-and-revalue workflow. It’s already faster because the kernel is vectorized. Then turn on adjoint Greeks when you’re ready.
You upgrade one pricer at a time. You see improvement at every step, not just at the end.
Where to start
In most trading books, 5 to 10 percent of instrument types eat 80 to 90 percent of the compute. Vanilla swaps under bump-and-revalue are fine. Callable exotics with Monte Carlo are where the budget goes.
The arithmetic
We measured this on a two-asset Asian option. 100,000 Monte Carlo scenarios, 252 timesteps, 214 Greeks: full delta, vega, and rho across every asset and tenor point.
| Method | Greeks | Time |
|---|---|---|
| Bump-and-revalue | 214 | 181 seconds (215 separate pricings) |
| Adjoint | 214 | 0.9 seconds (one forward + one backward pass) |
| Speedup | 201× |
The adjoint overhead relative to a price-only run is 30 to 47 percent depending on the product. For 214 sensitivities, you pay less than 1.5× the cost of a single pricing. Bump-and-revalue pays 215×.
In practice
Pick your most expensive pricer. Change double to idouble. Record the kernel. Run the cohort mirror. Validate Greeks against your existing bump-and-revalue output.
Then do the next instrument. The mechanics repeat. You keep bump-and-revalue running alongside for as long as you like.
Second-order and exotics
Gamma and cross-gamma use bump-on-adjoint: bump one input, rerun the adjoint. Cost is bumps times one adjoint pass, not repricings.
Monte Carlo exotics are where AAD helps most. The forward simulation is the forward pass. The adjoint handles path-dependent Greeks in one backward sweep. Discontinuities need smooth approximations, which takes some care. But it gets easier with each instrument you do.
SA-CVA
This might be the strongest reason to migrate.
SA-CVA needs sensitivities of CVA to credit spreads per counterparty per tenor, rates per currency per curve, FX, and more. Under bump-and-revalue, each sensitivity requires a full XVA simulation. A bank with 500 counterparties and 10 tenor points runs 5,000 full XVA sims per day for this alone.
With adjoint: one forward simulation, one backward pass, all sensitivities.
The timeline
January 2027 is nine months out. You don’t need to convert your entire library. You need to convert the five or ten instruments that are actually costing you money. If you want to see what this looks like on your own pricing library, I’m happy to walk through it.
Implemented using AADC, a commercial adjoint AD compiler (matlogica.com). Originally published on LinkedIn.