

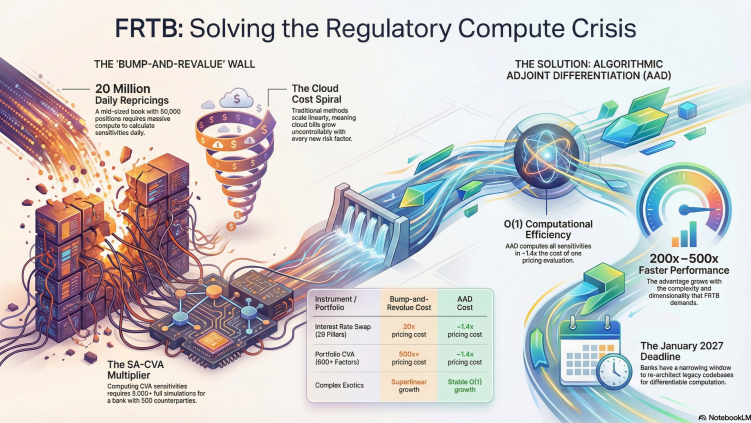
FRTB imposes heavy computational demands on market risk. The numbers are large and getting larger:
- FRTB-SA: 10,000 trades × 500 risk factors × 3 reprices = 15 million evaluations per day.
- FRTB-IMA: 250-day rolling history × 10,000 scenarios × full repricing. At many banks, this still runs over weekends.
The bottleneck is Greeks. Delta and vega surfaces for every risk factor, every trade, every day. Bump-and-revalue costs in risk factors — one full repricing per sensitivity.
What adjoint differentiation changes
A single adjoint pass computes all deltas simultaneously. Another gives you all vegas. The cost doesn’t grow with the number of risk factors.
We measured this on FRTB-IMA’s Sensitivities-Based Method:
| Method | Time | Speedup |
|---|---|---|
| Bump-and-revalue | 6 hours | — |
| Adjoint (one backward pass) | 11 minutes | 33× |
What that means in practice
FRTB-SA daily goes from a 4-hour batch to 30 minutes. FRTB-IMA moves from weekend processing to overnight. Intraday P&L attribution — exact risk-factor-level P&L explain at any point during the trading day — becomes feasible rather than aspirational. And regulators want sensitivities that match revaluation, which is exactly what adjoint Greeks give you. They’re mathematically exact, not finite-difference approximations.
The migration path
Most banks already have pricing engines — QuantLib, in-house, or vendor. The integration replaces double with an active type. The pricing logic stays the same. Operator overloading captures the computation graph at runtime; there’s no source transformation and no compiler plugins. Your existing tests still pass because the code hasn’t changed. The type has.
There’s a natural intermediate step. You validate first: record with the active type, replay forward-only, compare against your existing code path. Then use the recorded kernel for your existing bump-and-revalue workflow. It’s already faster because the kernel is vectorized. Turn on adjoint Greeks when you’re ready.
You upgrade one pricer at a time. Each step improves something.
Implemented using AADC, a commercial adjoint AD compiler (matlogica.com). Originally published on LinkedIn.