

A common question: why not just use JAX or PyTorch for adjoint differentiation in finance? They support automatic differentiation, they’re well-maintained, they have large communities.
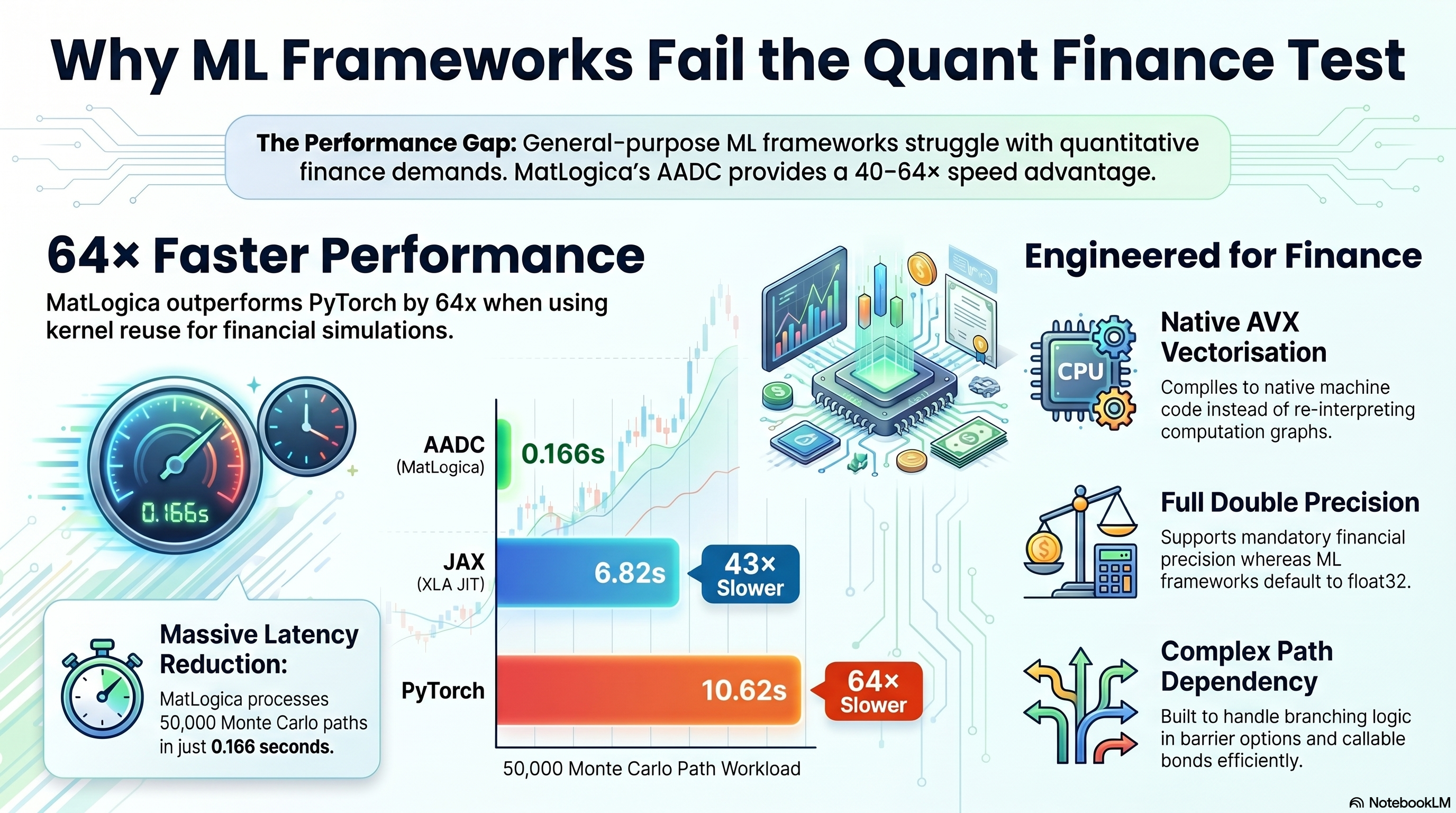
The answer is performance. We benchmarked on a representative quant workload: 50,000 Monte Carlo paths, 500 time steps, with full adjoint Greeks.
Results
| Framework | Time (s) | Speedup vs AADC |
|---|---|---|
| AADC | 0.166 | — |
| JAX (XLA JIT) | 6.82 | 43× slower |
| PyTorch | 10.62 | 64× slower |
| TensorFlow | 9.51 | 57× slower |
With kernel reuse (record once, evaluate many times with different inputs), the gap widens to 64×.
Why the gap exists
ML frameworks are designed for neural network training: large matrix multiplications, batch normalization, convolutions. Their automatic differentiation is optimized for these patterns.
Quantitative finance workloads look different:
- Path-dependent logic with branches and state (barrier options, callable bonds)
- Iterative calibration with solver loops
- Scalar operations accumulated over thousands of time steps
- Double precision throughout (ML frameworks default to float32)
The compiled kernel approach records the computation once, JIT-compiles it to native AVX-vectorized machine code, and replays it millions of times. ML frameworks reinterpret the computation graph on every call (even with JIT tracing), paying interpreter and framework overhead each time.
When ML frameworks are the right choice
- Neural network training (their core strength)
- Prototyping and exploration (better tooling, visualization)
- When the team already has PyTorch expertise and the workload is small enough that 40× doesn’t matter
When they’re not
- Production pricing with >1000 risk factors
- Real-time risk (latency matters)
- Monte Carlo with path-dependent payoffs
- Any workload where you need Greeks through complex financial logic
Benchmark methodology: same hardware, same data, same algorithm. AADC uses compiled kernel with AVX-2, 8 threads. JAX uses XLA JIT compilation. PyTorch uses torch.compile. TensorFlow uses tf.function with XLA. Implemented using AADC (matlogica.com).
Frequently Asked Questions
How much faster is AADC than JAX, PyTorch, and TensorFlow?
MatLogica AADC is 43x faster than JAX when including graph compilation time (0.166s vs 6.82s for a 50K path Monte Carlo simulation), and 64x faster when reusing compiled kernels. Overall, AADC provides 40-64x performance advantages over JAX, PyTorch, and TensorFlow for quantitative finance workloads.
Why is AADC faster than ML frameworks for quantitative finance?
AADC is optimized for quantitative finance workloads with 1,000+ nodes performing scalar operations, while ML frameworks like JAX, PyTorch, and TensorFlow are optimized for fewer nodes (<100) with large tensor operations. AADC optimizes at the scalar operation level and includes fast graph compilation.
Can AADC be used for machine learning applications?
Yes, AADC excels in specific ML applications including time series prediction, optimal control problems, and neural networks with up to 50,000 parameters. Research by Prof. Roland Olsson shows AADC can evaluate 10 million candidate neurons significantly faster than JAX or PyTorch.